

- The 5 Building Blocks: A Digital Transformation Framework That Actually Works
- The Pattern Behind the Building Blocks: Why Each One Matters
- Operational Excellence: The Foundation That Makes AI Transformation Possible
- Customer Intelligence: Why B2B Companies Can’t Use the Data They Already Have
- Product Intelligence: Why Your Smart Products Are Failing (And What Actually Works)
- Data Mastery: The Information Flow Problem Behind Every AI Initiative
- Team Dynamics: Why Your Biggest AI Challenge Isn’t Technical
Every technology project comes down to two things: getting information into systems or getting information out. Understanding this pattern changes how you approach digital transformation - and determines whether AI creates value or just complexity.
Every technology project you’ve ever done comes down to two things: getting information into systems or getting information out of systems. That’s it. Everything else is implementation details.
New ERP system? You’re getting transaction data in so the system can process orders and track inventory. Business intelligence platform? You’re getting insights out so people can make decisions. E-commerce website? Getting product data in, getting order data out. IoT sensors? Getting telemetry in. AI models? Getting predictions out.
The technology vendors will complicate this with architecture diagrams and integration capabilities. Your IT team will debate databases and APIs. Consultants will present maturity models. But strip away that complexity and you’re left with the fundamental challenge: information needs to flow from where it is to where it needs to be, in a format that’s actually useful.
This sounds reductive. But understanding this pattern changes how you approach digital transformation. It shifts focus from technology selection to information flow design. It highlights that data integration and quality aren’t IT problems to solve after you pick the software – they’re the actual work that determines whether your initiative creates value. Achieving data mastery involves recognizing this crucial aspect.
And here’s the uncomfortable truth: if you think it’s hard to get numerical data out of an ERP system, wait until you try to get process knowledge out of a human being.
Data Mastery is the fourth of the building blocks for your digital transformation. It depends on all three previous blocks – operational excellence gives you transaction data, customer connection gives you relationship data, Product Intelligence gives you product usage data. Data Mastery is where you integrate these disconnected information flows into something coherent that actually drives decisions.
The Opportunity You Can’t See
A diversified industrial company had grown through acquisition over fifteen years. Twenty manufacturing businesses – pumps, valves, fittings, filtration systems. Each operated independently with its own systems. The CFO saw an opportunity in centralized purchasing. These businesses collectively spent hundreds of millions annually. Aggregate that purchasing power and negotiate better pricing – potentially saving millions.
Back-of-napkin analysis looked compelling. Purchasing consultants validated it through supplier conversations. Yes, suppliers would sharpen pricing for consolidated volume. Corporate approved the initiative.
Then they tried to see what everyone was spending. Each portfolio company had different ERP systems – SAP, Oracle, industry-specific packages. Different chart of accounts, vendor naming conventions, part numbering schemes, purchasing categories. One company coded steel purchases by grade and thickness. Another by supplier and application. A third by project. Corporate couldn’t aggregate “steel spending” without manual reconciliation.
The consultants started with spreadsheet exercises. Each company extracted top suppliers and spending by category, normalized vendor names, mapped to standard categories. Corporate compiled twenty spreadsheets into a master view.
The analysis revealed the opportunity was real. But executing consolidated purchasing required ongoing visibility, not quarterly spreadsheets. They needed systems tracking commitments against contracts, flagging off-contract spending, aggregating demand forecasts. None of that was possible manually.
The information existed but couldn’t be accessed systematically. Transaction data sat in operational systems designed to run individual businesses, not provide portfolio visibility. The opportunity was getting information out of twenty disconnected systems into a format enabling portfolio-wide decisions.
The Architecture Decision Nobody Wants to Make
A different company needed to consolidate financial reporting from dozens of business units into corporate statements. Monthly closes required enormous manual effort – extracting data, applying translation rules to map accounts between systems, loading into the consolidation tool.
The CFO wanted automation. Consultants designed a solution but hit a fundamental architecture decision: where should translation rules live?
Edge-based: Push translation logic to each source system. Each business unit configures their ERP to output data already mapped to corporate standards. Cleaner architecturally – translate where data lives.
Center-based: Pull raw data from sources and apply translation centrally. Corporate owns all mapping logic in one place but handles twenty different formats.
The technical team debated for weeks. What nobody wanted to acknowledge: the architecture decision didn’t matter nearly as much as everyone thought. The hard work was identical either way – documenting how each source system mapped to corporate standards, capturing exceptions, getting controllers to validate rules, testing thoroughly.
Whether rules lived in twenty systems or one central system, somebody had to define them, code them, maintain them. The architecture decision was about where to store and execute rules, not about avoiding the work.
Even more painfully, none of this delivered value by itself. All this effort just got information into the consolidation tool. Phase one delivered automated data collection but didn’t change what corporate could do with data. The value – faster closes, better analysis – came in phase two when they actually used consolidated data differently.
This is the brutal truth about data integration. Getting information flowing doesn’t create value. Doing something better with that information creates value. But you can’t skip integration work, because until information flows reliably, you can’t build anything on top of it.
When Integration Actually Pays Off
Not every data integration project suffers through years before delivering value. Sometimes connecting data sources reveals insights immediately.
A manufacturer had excellent operational data – costs tracked accurately, gross margins by product. They also had good customer data in CRM – sales history, relationships, contract terms. What they didn’t have was integrated customer-product profitability analysis. Nobody could answer “which customers are actually profitable when you account for all costs to serve them?”
Product margins didn’t include service costs specific to certain customers. High-touch customers with lots of engineering support, expedited shipments, or high return rates consumed resources not reflected in product cost accounting.
The company integrated data from multiple sources: sales and margins from ERP, service costs from the service system, freight from transportation, returns from quality, engineering time from project tracking. Months of data mapping and cleansing. But when they ran the analysis, insights appeared immediately.
Several high-volume customers showed up as deeply unprofitable once service costs were included. Large orders, regular purchases, well-known brands – but burning through service resources. Gross margin looked good. Net profitability was terrible.
Conversely, some smaller customers showed exceptional profitability. Standard products, minimal service, paid on time, never returned anything. Lower volume, but among the most profitable relationships.
The company restructured their approach. For unprofitable high-service customers, they implemented service agreements with separate pricing. For highly profitable low-touch customers, they focused on growth. Within the first year, profitability shifts were measurable.
This is what makes data integration worthwhile. The value isn’t in dashboards or database schemas. It’s in decisions that change because you can finally see patterns hidden across disconnected systems.
The Knowledge That’s Even Harder to Capture
Transaction data trapped in disconnected systems is solvable. Process knowledge trapped in people’s heads is a different magnitude of challenge.
During a wave of M&A in industrial services, companies weren’t buying targets primarily for revenue. They were buying talent – senior engineers who understood how specific infrastructure systems worked. Pipeline inspection protocols. Refinery maintenance procedures. These engineers were retiring. Their knowledge was irreplaceable.
Acquiring companies bought time to capture knowledge before it walked out the door. M&A business cases explicitly valued knowledge transfer programs and apprenticeship arrangements.
But knowledge capture was harder than expected. Most engineers aren’t writers. Converting tacit knowledge developed through years of experience into explicit documentation is genuinely difficult. How do you write down intuition about what unusual vibration patterns mean?
The cultural problems ran deeper. People recognized their specialized knowledge made them valuable. Documenting knowledge and training others felt like reducing their own value. Why would they?
Some organizations handled this with incentives, making knowledge transfer part of performance objectives. Others focused on apprenticeship models – pairing senior and junior engineers so knowledge transferred through doing rather than documenting.
But even successful programs never captured everything. Some expertise remained tacit, impossible to fully articulate. The best organizations could do was reduce dependence on individual experts while acknowledging some knowledge would always be personal.
This matters for AI because process knowledge is often more valuable than transaction data. AI can analyze ERP patterns. But AI can’t replicate experienced engineer judgment. AI can help, but only if you can capture enough process knowledge to train models effectively.
How AI Changes the Data Challenge
AI doesn’t eliminate data integration and quality work. It makes it more critical. AI amplifies whatever data foundation you’ve built. Clean, integrated data leads to valuable AI applications. Messy, disconnected data leads to AI failures.
Traditional business intelligence could work with imperfect data. If dashboards showed slightly incorrect numbers, human analysts applied judgment and context. AI doesn’t have that judgment. It takes data at face value. Inconsistent product categorization creates inconsistent AI recommendations. Mismatched customer identifiers prevent coherent customer profiles.
The foundational data work – integration, cleansing, governance – becomes prerequisite for AI. Companies that invested in data infrastructure are ready for AI. Companies that skipped that work now must build the foundation first.
Consider customer profitability. The integration connecting sales, service, logistics, and quality created immediate value. But it also created foundation for AI: predicting which prospects become profitable customers, recommending optimal service approaches, identifying early warning signs of unprofitability.
Those AI applications only work if underlying data integration is solid.
Building Data Mastery That Actually Works
When executives ask about improving data capabilities, they want to talk about platforms – data warehouses, lakes, master data management. Those can help. But they’re not the foundation.
The foundation is recognizing every technology initiative is really about information flow. Getting data in where it needs processing. Getting data out where it needs analysis. Specific technologies matter less than whether you’ve designed information flows correctly and built discipline to maintain quality.
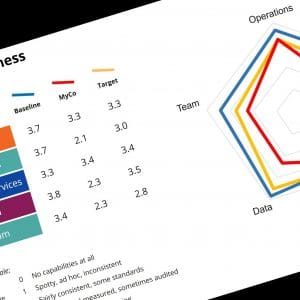
Here’s how to assess readiness:
Can you answer cross-functional questions without massive manual effort? If someone asks about customer profitability including service costs, or supplier performance across portfolio companies – can you answer with data rather than guesswork? If it takes three days and spreadsheets, you have integration problems limiting AI initiatives.
Do you know where critical knowledge lives? Not just transaction data in systems, but process knowledge in people’s heads. Have you identified valuable knowledge at risk? Do you have approaches for capturing it?
Can you trust data quality? When you look at reports, do you understand where numbers came from and whether they’re reliable? Data quality mysteries every time something looks wrong means you lack governance foundation AI requires.
Do different parts of your organization use common definitions? If Sales, Finance, and Operations define “customer” differently, AI will amplify inconsistencies rather than resolve them.
Companies that built strong data capabilities did it through discipline, not technology. They invested in integration when immediate ROI wasn’t obvious. They built governance to maintain quality even though it felt bureaucratic. They worked on knowledge capture even though documentation is hard.
That discipline makes AI possible.
The Work That Comes First
If you’re frustrated by how hard it is to answer cross-functional questions, you’re in a good position. You’ve identified which information flows matter. You know which integration points create problems. That awareness is the starting point.
Companies struggling with data never invested in designing information flows deliberately. They’re still treating each system independently. They’re still relying on manual spreadsheets. They’re still working around data quality problems rather than fixing root causes.
Your data foundation doesn’t need perfection for AI. It needs to be good enough that information flows reliably. The same integration enabling customer profitability analysis enables AI-powered customer scoring. The same governance improving financial consolidation enables AI forecasting.
AI is the fourth transformation wave, but it builds on data foundations from previous waves. Companies that invested in integration and governance have capabilities that can’t be quickly replicated.
Your systems might be sitting on exactly the data your AI initiatives need – if you’ve invested in getting information flowing and maintaining quality. The question isn’t whether you have enough data for AI. The question is whether you’ve built discipline to move information where it needs to go and trust it when it gets there.
Recommended Books
- Data Management at Scale by Piethein Strengholt – Modern approaches to enterprise data architecture and integration
- The Knowledge-Creating Company by Ikujiro Nonaka – The classic on capturing tacit knowledge and making it organizational
- Competing on Analytics by Thomas Davenport – How integrated data becomes sustainable competitive advantage
If you’re wrestling with data integration challenges or preparing your organization for AI, I’d love to hear what’s working and what’s not. Join my mailing list for weekly insights on digital transformation that actually works.
2 February, 2026

Comments (0)